
Unlocking the true potential of Apache Spark in production environments has been a quest for many data engineers. While platforms like Databricks offer a seamless experience for cluster creation and Spark job orchestration, they come with certain downsides such as high costs and potential vendor lock-in. As a result, the search for an open-source solution that combines the power of Spark with efficient orchestration continues. In this blog post, we will venture on a journey to explore a robust and cost-effective approach to running Spark in production - deploying Spark on Kubernetes and orchestrating it with Apache Airflow. By leveraging the flexibility and scalability of Kubernetes and the workflow capabilities of Airflow, we can achieve a highly customizable and open solution to handle our data processing tasks efficiently. Join us as we explore into the world of Spark on Kubernetes and discover how the combination of these open-source tools empowers us to build, manage, and scale our Spark applications with ease.

In this guide, we will take you on a journey through the installation and orchestration of Apache Spark on Kubernetes, leveraging the power of Azure Cloud. Over the next sections, we will walk you through the step-by-step process of setting up Spark on Azure Kubernetes cluster, and demonstrate how Airflow can create and schedule data workflows efficiently. So, fasten your seatbelts, and let’s dive into the world of Apache Spark on Kubernetes!
Prerequisites
Before diving into the exciting world of deploying Apache Spark on Kubernetes there are a few essential prerequisites that need to be in place. To follow along with the demo, ensure you have the following:
- Azure Kubernetes Service (AKS): You should have access to an Azure Kubernetes Service cluster, as we will be leveraging this managed Kubernetes environment for our Spark deployments.
- Azure Container Registry: Make sure you have set up an Azure Container Registry to store and manage Docker images. This registry will serve as the repository for our custom Spark image.
- Docker: Docker must be installed on your local machine. This will enable you to build, manage, and run Docker images locally.
- Helm: Helm, the package manager for Kubernetes, should also be installed on your local machine. Helm simplifies the deployment of applications on Kubernetes using pre-configured charts.
NOTE: while the example in this post is based on a cloud environment, you can also follow the guide to install Spark on a local Kubernetes cluster and set up a Docker registry container. The principles and steps remain similar regardless of whether you are deploying on a cloud or a local.
Spark on Kubernates
In Kubernetes, users are expected to provide container images that can be deployed within pods. These images are specifically designed to run in a container runtime environment supported by Kubernetes. In the upcoming section, we will delve into the process of building and publishing Docker images, essential components for interfacing with the Kubernetes backend.
Spark Docker Image
Starting from version 2.3, Spark offers a pre-configured Dockerfile, residing in the kubernetes/dockerfiles/ directory, tailored for seamless integration with Kubernetes. Alternatively, users have the flexibility to customize this Dockerfile to align with their specific application requirements. Moreover, Spark provides a convenient bin/docker-image-tool.sh script, simplifying the process of building and publishing Docker images intended for use within the Kubernetes backend. This handy tool easy the creation and management of Docker images, empowering users to optimize Spark’s deployment in Kubernetes clusters efficiently.
So, to build a docker image first you need to download Spark (Pre built for Hadoop). Then, unzip and locate into the folder and run:
1
$ ./bin/docker-image-tool.sh -r <repo> -t my-tag build
By default bin/docker-image-tool.sh builds docker image for running JVM jobs. For additional language binding docker images:
For python:
1
$ ./bin/docker-image-tool.sh -r <repo> -t my-tag -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile build
In this demo, we will craft a custom Spark image that incorporates the necessary components, including a PySpark job. To achieve this, I have created a dedicated folder within kubernetes/dockerfiles/spark/bindings/. Inside this folder, you will find the Python-based PySpark job along with a custom Dockerfile tailored to include the python codes. By customizing the Dockerfile, we can seamlessly integrate the jobs into the Spark image, ensuring the image encapsulates all the dependencies and configurations required for smooth execution of PySpark jobs. This approach allows us to create a self-contained and portable container, empowering you to deploy and scale the applications.
In summary, to customize our Spark image, we have created a new folder called my-python within the directory kubernetes/dockerfiles/spark/bindings. Inside this folder:
my-libs Folder: This folder contains our custom PySpark job, a simple word count script, and a sample file.txt utilized for testing purposes.
Custom Dockerfile: We have crafted a Dockerfile based on the one provided by Spark in kubernetes/dockerfiles/spark/bindings/python/Dockerfile. However, we have tailored it to include all the contents of our my-libs folder. By doing so, we ensure that the resulting image contains our custom Python libraries and dependencies, enabling seamless execution of our PySpark job within the containerized environment.
PySpark Job (kubernetes/dockerfiles/spark/bindings/my-python/my-libs/wordcount.py):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import sys
from operator import add
from pyspark.sql import SparkSession
DEFAULT_FILE="/opt/spark/my-libs/file.txt"
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Use default file")
file_path = DEFAULT_FILE
else:
file_path = sys.argv[1]
spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
lines = spark.read.text(file_path).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add) \
.map(lambda x: (x[1], x[0])) \
.sortByKey()
output = counts.collect()
for (count, word) in output:
print(f"{word}:{count}")
spark.stop()
Text file (kubernetes/dockerfiles/spark/bindings/my-python/my-libs/file.txt):
1
2
3
4
5
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Nam eget iaculis ex. Aliquam vulputate, tortor at consectetur accumsan,
sapien ante lacinia tortor, eu cursus neque felis at lacus.
Quisque tempor vel elit sit amet laoreet. Vivamus elementum mauris tortor, vitae consequat dui venenatis vitae. Sed iaculis nunc vitae imperdiet convallis. Donec in maximus ipsum. Quisque eu aliquam mauris, suscipit iaculis mi.
In viverra nulla eget iaculis sodales. Integer est est, iaculis vitae molestie ac, iaculis ac est. Donec id bibendum dui. Integer id mollis sapien. Cras ullamcorper sapien eu egestas tristique. Aliquam massa libero, pretium ac enim fermentum, ultricies commodo turpis. Quisque id est eget magna porttitor sagittis. Donec eros ante, placerat et elit in, euismod elementum augue. Interdum et malesuada fames ac ante ipsum primis in faucibus. Vestibulum mollis neque eget metus efficitur, ut pretium purus mollis. Vivamus nec nisl sit amet erat fermentum dignissim. Nunc accumsan leo vel tincidunt venenatis. Proin vel scelerisque nisi. Nulla est leo, viverra vitae condimentum et, ullamcorper sed est. Phasellus fringilla mattis ullamcorper.
Dockerfile (kubernetes/dockerfiles/spark/bindings/my-python/Dockerfile)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
ARG base_img
FROM --platform=linux/amd64 $base_img
WORKDIR /
# Reset to root to run installation tasks
USER 0
RUN mkdir ${SPARK_HOME}/python
RUN apt-get update && \
apt install -y python3 python3-pip && \
pip3 install --upgrade pip setuptools && \
# Removed the .cache to save space
rm -rf /root/.cache && rm -rf /var/cache/apt/* && rm -rf /var/lib/apt/lists/*
COPY python/pyspark ${SPARK_HOME}/python/pyspark
COPY python/lib ${SPARK_HOME}/python/lib
COPY kubernetes/dockerfiles/spark/bindings/my-python/my-libs/* /opt/spark/my-libs/
WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
ARG spark_uid=185
USER ${spark_uid}
Now we are ready to build the image:
1
2
3
4
5
6
#Login to azure
az login
#Login to azure container registry
az acr login --name dockercr1.azurecr.io
#Then, build and push the image
./bin/docker-image-tool.sh -X -r dockercr1.azurecr.io -t 3.4.1 -p ./kubernetes/dockerfiles/spark/bindings/my-python/Dockerfile build
Note: I added the -X parameter to use docker buildx to cross build the image because I’m using Apple M1 processor. The -X also push the image after the build, if you don’t use the -X then you need to push the image with: docker push dockercr1.azurecr.io/spark-py:3.4.1
Now we can test the image running the pyspark job:
1
docker run --rm dockercr1.azurecr.io/spark-py:3.4.1 /opt/spark/bin/spark-submit --master local /opt/spark/my-libs/wordcount.py
Upon successful execution, you will witness the delightful outcome of our script, displaying the frequency of each word present in the dataset:
1
2
3
4
5
6
7
8
9
10
11
Lorem:1
dolor:1
...
vel:3
Donec:3
est:3
ac:3
id:3
eget:4
vitae:4
iaculis:6
Spark Operator
The Spark Operator is a powerful tool designed to simplify the deployment and management of Apache Spark applications on Kubernetes clusters. It acts as a Kubernetes-native controller, abstracting the complexities of setting up and maintaining Spark clusters, making it easier for users to leverage Spark’s capabilities within a containerized environment. So, Spark Operator simplifies the management of Spark applications on Kubernetes, providing automation, scalability, and seamless integration within the Kubernetes ecosystem.
To quickly install the operator into your kubernates, you can use the Helm chart:
1
2
3
4
5
6
7
8
# Add the repo
helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator
# Install the chart
helm install my-spark spark-operator/spark-operator --namespace spark-operator --create-namespace
# Verify the installation
helm list -A
#Check the spark operator pod is running
kubectl get pods -n spark-operator
If the installation was successful with the last command you should be able to see the spark operator pod running:
1
2
NAME READY STATUS RESTARTS AGE
my-spark-spark-operator-6b969f4b7c-djck8 1/1 Running 2 (2m27s ago) 18h
The Spark driver pod relies on a Kubernetes service account to interact with the Kubernetes API server for creating and monitoring executor pods. For the driver to function properly, the service account must possess the necessary permissions. So, the service account should be granted a Role or ClusterRole enabling the creation of pods and services. Then, you need to create a custom service account:
1
kubectl create serviceaccount spark
And then, grant a service account a Role or ClusterRole, a RoleBinding or ClusterRoleBinding:
1
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
SparkApplication
Now we are ready to test our spark application in kubernates using the SparkApplication object. The spark operator enables the usage of SparkApplication Kubernetes objects and submits the application.
Following the yaml file my-wordcount.yaml with the our SparkApplication configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: my-wordcount
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "dockercr1.azurecr.io/spark-py:3.4.1"
imagePullPolicy: Always
mainApplicationFile: local:///opt/spark/my-libs/wordcount.py
arguments:
- "/opt/spark/my-libs/wordcount.py"
sparkVersion: "3.4.1"
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.4.1
serviceAccount: spark
executor:
cores: 1
instances: 2
memory: "512m"
labels:
version: 3.4.1
This YAML configuration defines a SparkApplication resource for Kubernetes. The application is named my-wordcount and is intended for execution within the default namespace. The specified Docker image dockercr1.azurecr.io/spark-py:3.4.1 is the image that we build in the previous section. The main Spark application file “wordcount.py” is located at “local:///opt/spark/my-libs/wordcount.py” and is the pyspark job that we define in the previous section. Finally we define the cluster configuration with one driver and 2 workers (executors).
Now we can submit the spark application with:
1
kubectl apply -f ./my-wordcount.yaml
And then you can monitor the status with:
1
kubectl get sparkapplications
To identifying the driver pod and workers created by the spark operator that we submitted in the default namespace:
1
2
3
4
5
$kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
my-wordcount-driver 1/1 Running 0 9s
pythonwordcount-ebfe3a89bb17f376-exec-1 1/1 Running 0 1s
pythonwordcount-ebfe3a89bb17f376-exec-2 0/1 Pending 0 1s
Note: The Spark Operator has created one driver pod and two worker pods, as specified in the YAML file. The workers will be automatically deleted once the job completes. This automated process ensures efficient resource management and optimizes cluster utilization, making the Spark Operator an ideal choice for scalable and cost-effective data processing workflows. Enjoy the smooth execution of your Spark jobs ;)
Upon successful completion, you will witness the following result:
1
2
3
$kubectl get sparkapplications
NAME STATUS ATTEMPTS START FINISH AGE
my-wordcount COMPLETED 1 2023-08-03T10:49:26Z 2023-08-03T10:52:27Z 20h
You can access its logs and inspect the result of our Spark job using the following command:
1
kubectl logs my-wordcount-driver -n default
To delete the spark application:
1
kubectl delete sparkapplications my-wordcount
Orchestrating Spark
Up until now, we have been able to submit and manage Spark applications using kubectl commands. However, for more robust management and orchestration of Spark applications, we require a more sophisticated solution. Apache Airflow is an excellent open-source platform for workflow automation and job orchestration. With Airflow, you can define and orchestrate jobs using Directed Acyclic Graphs (DAGs), providing a powerful way to schedule, monitor, and manage complex data workflows. Now, let’s explore how to create an instance of Airflow within Kubernetes, enabling seamless integration of Spark applications with Airflow’s orchestration capabilities.
Airflow on Kubernates
To install Airflow chart using Helm, run the following commands:
1
2
helm repo add apache-airflow https://airflow.apache.org
helm upgrade --install airflow apache-airflow/airflow --namespace airflow --create-namespace
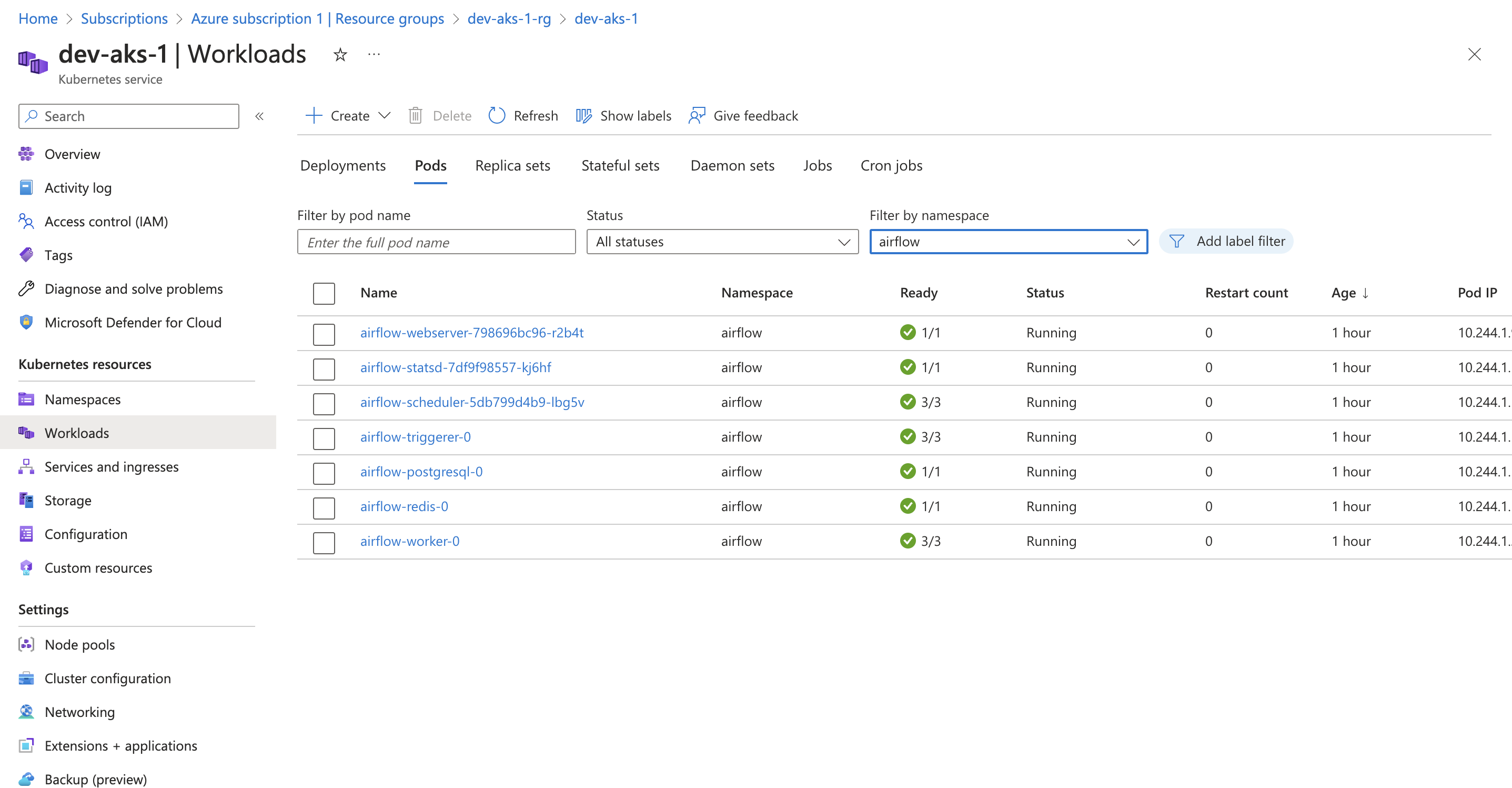
Upon executing the command, Airflow will be deployed on the Kubernetes cluster using the default configuration. After successful installation, you will be able to view all the related pods by running the following command:
1
kubectl get pods -n airflow
The output will provide a comprehensive overview of the deployed pods and their statuses:
1
2
3
4
5
6
7
8
NAME READY STATUS RESTARTS AGE
airflow-postgresql-0 1/1 Running 0 75m
airflow-redis-0 1/1 Running 0 75m
airflow-scheduler-5db799d4b9-lbg5v 3/3 Running 0 75m
airflow-statsd-7df9f98557-kj6hf 1/1 Running 0 75m
airflow-triggerer-0 3/3 Running 0 75m
airflow-webserver-798696bc96-r2b4t 1/1 Running 0 75m
airflow-worker-0 3/3 Running 0 69m
Airflow Git Sync
By default, Airflow takes its DAG definitions from the folder ~/airflow/dags. However, there is a powerful configuration option that allows you to connect Airflow with a Git repository. This integration enables you to modify your DAGs directly from the Git repository, with automatic synchronization to your Airflow instance. So let’s illustrate the process using GitHub as an example.
Start by setting up a GitHub repository. You can use your existing repository or create a new one. For example: https://github.com/dave90/airflow-dags
Generate a pair of public and private SSH keys using the ssh-keygen command in your terminal (command should generate 2 files id_rsa and id_rsa.pub):
1
ssh-keygen -t rsa -b 4096 -C "<YOUR EMAIL>"
After generating the SSH keys, go to your GitHub repository’s settings. Look for the “Deploy Keys” section and add your public key (contents of the .pub file) to enable secure communication between your Airflow instance and the repository.

Next, you’ll need to create a Kubernetes secret to store both the private key (id_rsa) and the public key (id_rsa.pub) for secure communication between Airflow and your GitHub repository.
To create the Kubernetes secret, run the following command:
1
kubectl create secret generic airflow-ssh-secret --from-file=gitSshKey=./id_rsa --from-file=id_ed25519.pub=./id_rsa.pub -n airflow
To enable Git synchronization in Airflow, we’ll create a YAML configuration file named values-sync.yml with the following content:
1
2
3
4
5
6
7
8
dags:
gitSync:
repo: https://github.com/dave90/airflow-dags.git
branch: main
enabled: true
subPath: src/
credentialsSecret: git-credentials
sshKeySecret: airflow-ssh-secret
This configuration file specifies the repository and branch from which Airflow should sync DAGs. Setting enabled true activates the synchronization feature, and subPath: src/ specifies the directory within the repository where the DAGs are located and the SSH key needed for secure communication is stored in the Kubernetes secret named airflow-ssh-secret (previously created).
To apply this configuration to Airflow, use the following command:
1
helm upgrade --install airflow apache-airflow/airflow --namespace airflow --create-namespace -f values-sync.yml
To test the setup and configuration, you can add a simple test DAG named test_dag.py to your Git repository under the src/ folder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from airflow.decorators import dag, task
import pendulum
@dag(
schedule_interval=None,
start_date=pendulum.datetime(2021, 1, 1, tz='UTC'),
catchup=False,
tags=['sample']
)
def sample_etl():
@task()
def extract():
print("Extract")
@task()
def transform():
print("Transform")
@task()
def load():
print("Load")
extract() >> transform() >> load()
sample_dag = sample_etl()
With this test DAG defined, you can now connect to Airflow using the following command:
1
kubectl port-forward svc/airflow-webserver 8080:8080 --namespace airflow
After running the port-forwarding command, open your browser and navigate to 127.0.0.1:8080. Here, you should be able to access the Airflow web interface. Upon successful connection, you will find the sample_etl DAG, which you defined earlier, listed in the Airflow interface. With your DAG ready, you can manually trigger its execution by clicking the play button. This action initiates the DAG run the workflow.
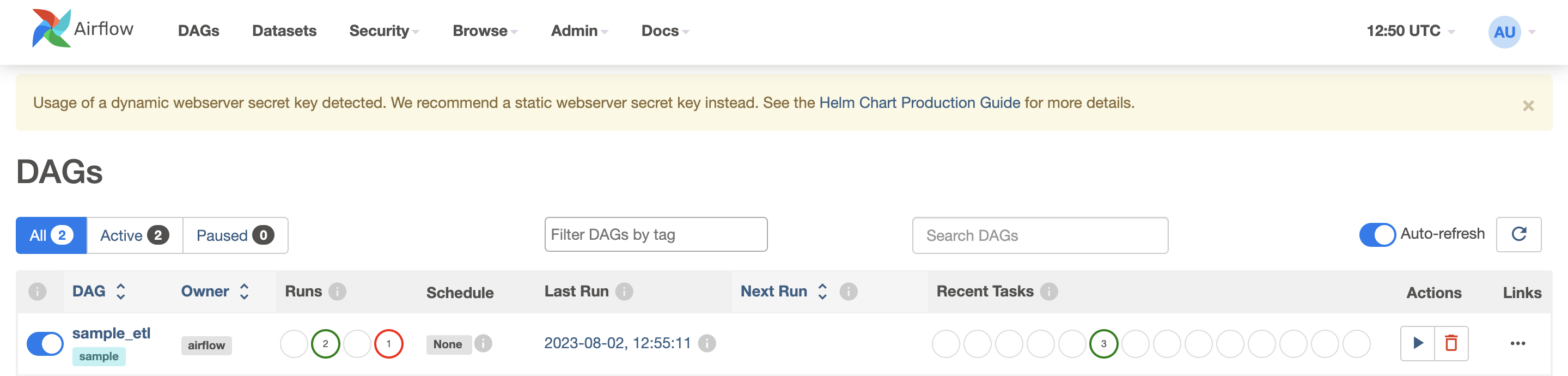
Airflow Spark Kubernetes Operator
To enable the connection between Airflow and the Kubernetes cluster, we need to set up a Kubernetes connection in Airflow.
So first step is to obtain the Kubernetes config (credentials) in JSON format by running the following command:
1
kubectl config view --flatten -o json
Then, create a new Kubernetes connection in Airflow. Go to the Airflow web interface, and under the “Admin” tab, select “Connections.” Click on the “Create” button to add a new connection.
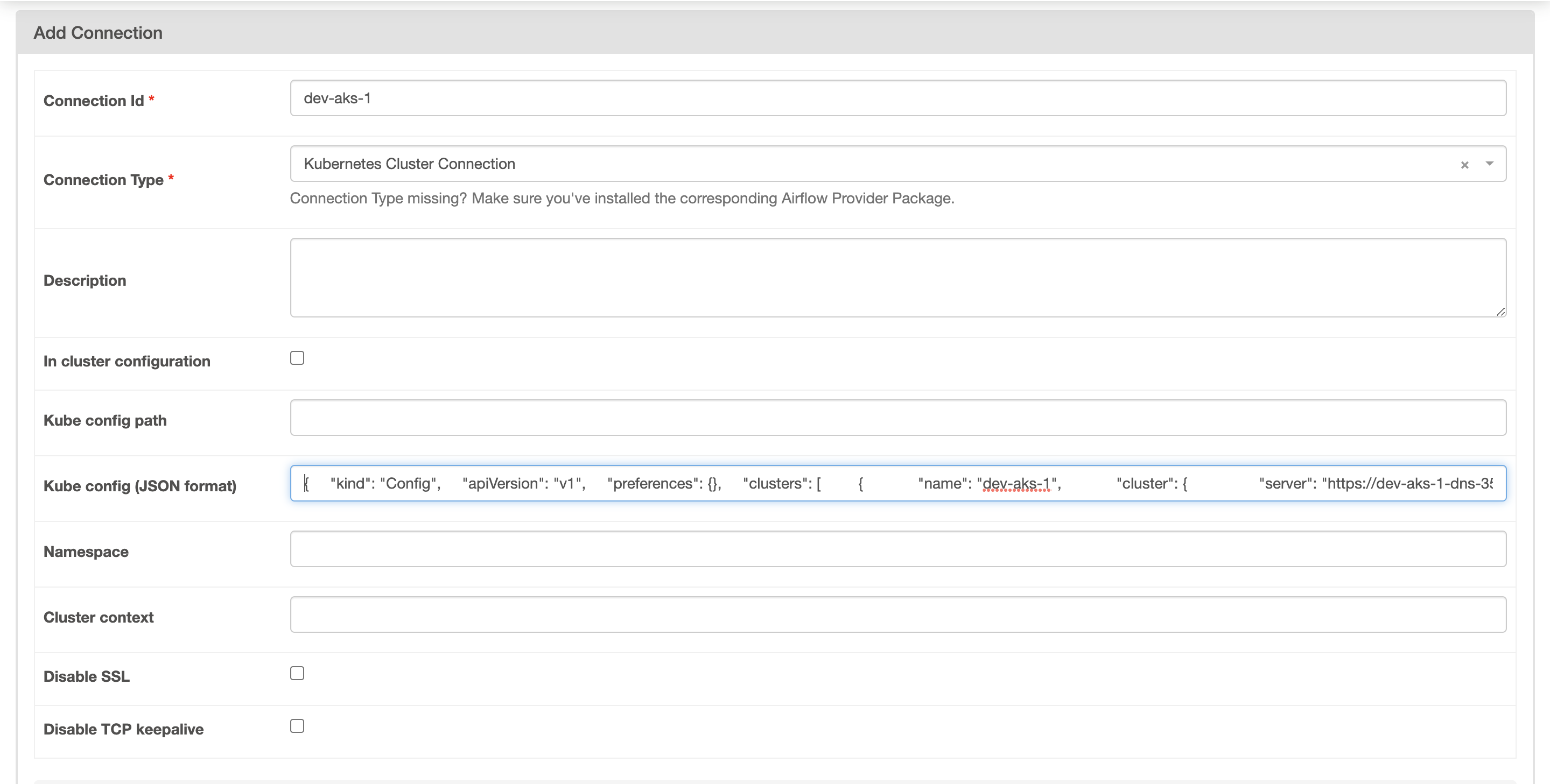
Select the Connection type: Kubernates Cluster Connection, fill the Connection ID and Kube Config (JSON) and then save the connection by clicking on the “Save” button.
To orchestrate the Spark jobs, we’ll create two YAML files, my-wordcount-1.yaml and my-wordcount-2.yaml, each defining a SparkApplication. These YAML files differ in the arguments passed to the PySpark job.
src/my-wordcount-1.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: my-wordcount-1--
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "dockercr1.azurecr.io/spark-py:3.4.1"
imagePullPolicy: Always
mainApplicationFile: local:///opt/spark/my-libs/wordcount.py
arguments:
- "/opt/spark/my-libs/wordcount.py"
sparkVersion: "3.4.1"
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.4.1
serviceAccount: spark
executor:
cores: 1
instances: 2
memory: "512m"
labels:
version: 3.4.1
src/my-wordcount-2.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: my-wordcount-2--
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "dockercr1.azurecr.io/spark-py:3.4.1"
imagePullPolicy: Always
mainApplicationFile: local:///opt/spark/my-libs/wordcount.py
arguments:
- "/opt/spark/my-libs/file.txt"
sparkVersion: "3.4.1"
restartPolicy:
type: OnFailure
onFailureRetries: 3
onFailureRetryInterval: 10
onSubmissionFailureRetries: 5
onSubmissionFailureRetryInterval: 20
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.4.1
serviceAccount: spark
executor:
cores: 1
instances: 2
memory: "512m"
labels:
version: 3.4.1
Next, we’ll create the DAG file, wordcount-dag.py, that will trigger the Spark jobs:
src/wordcount-dag.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
from datetime import timedelta, datetime
# [START import_module]
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.providers.cncf.kubernetes.operators.spark_kubernetes import SparkKubernetesOperator
from airflow.providers.cncf.kubernetes.sensors.spark_kubernetes import SparkKubernetesSensor
from airflow.utils.dates import days_ago
# [END import_module]
# [START default_args]
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': days_ago(1),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'max_active_runs': 1,
'retries': 0
}
# [END default_args]
# [START instantiate_dag]
dag = DAG(
'wordcount',
default_args=default_args,
schedule_interval=timedelta(days=1),
tags=['example']
)
# spark = open(
# "example_spark_kubernetes_operator_pi.yaml").read()
submit_1 = SparkKubernetesOperator(
task_id='wordcount_submit_1',
namespace="default",
application_file="my-wordcount-1.yaml",
kubernetes_conn_id="dev-aks-1",
do_xcom_push=True,
dag=dag,
api_group="sparkoperator.k8s.io",
api_version="v1beta2"
)
submit_2 = SparkKubernetesOperator(
task_id='wordcount_submit_2',
namespace="default",
application_file="my-wordcount-2.yaml",
kubernetes_conn_id="dev-aks-1",
do_xcom_push=True,
dag=dag,
api_group="sparkoperator.k8s.io",
api_version="v1beta2"
)
submit_1 >> submit_2
This DAG, named “wordcount,” will run daily, triggering two Spark jobs in sequence. The SparkKubernetesOperator is used to submit the SparkApplications, each using the respective YAML files defined earlier. The tasks are connected with submit_1 » submit_2 to ensure the second job runs after the first job has successfully completed.
NOTE: dev-aks-1 is the Connection ID previously created in Airflow.
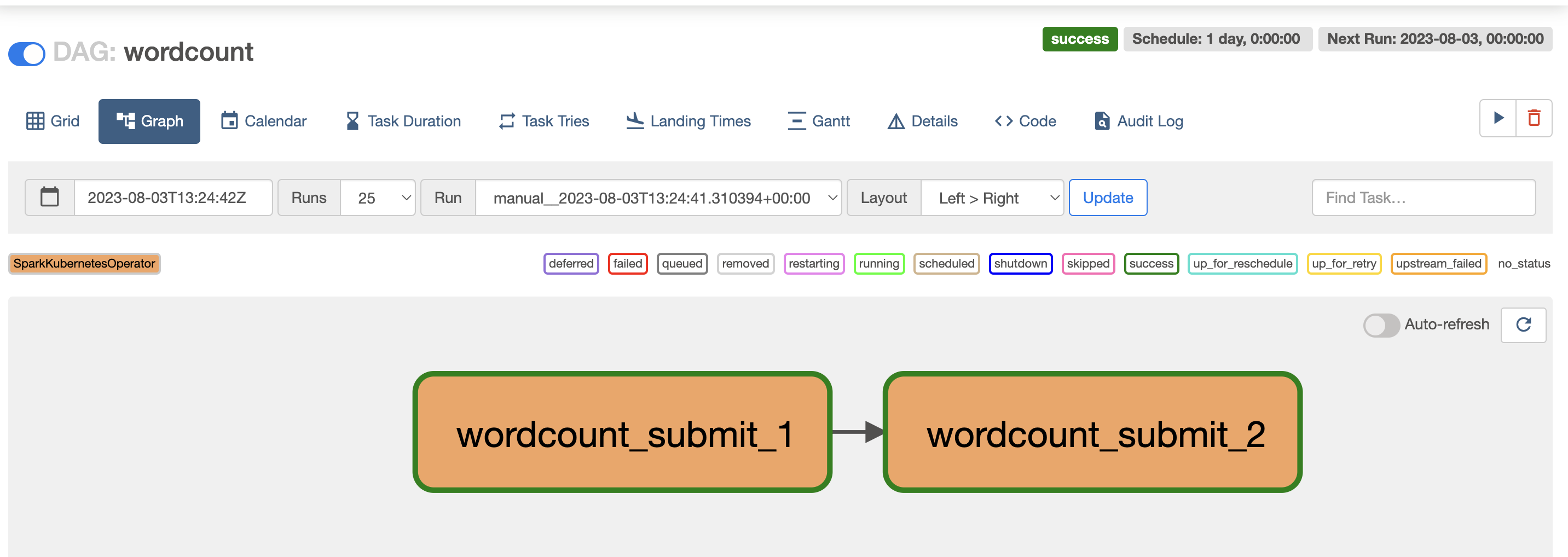
It’s important to note that the name of the SparkApplication in the YAML definition includes a timestamp, {{ ts_nodash | lower }}, and the task instance number, {{ task_instance.try_number }}. This dynamic naming ensures that each run generates a unique SparkApplication name, capturing the full history of pods within Kubernetes and maintaining a clear record of each job execution, making it easier to trace back and analyze historical runs. However, it’s crucial to manage pod cleanup to avoid an excessive accumulation of pods.
Final Demo
With the wordcount DAG ready, we can finally trigger its execution by clicking the play button.
Clicking on the DAG name in the web interface allows you to access a comprehensive overview of all the past DAG runs. Each run is represented with its respective status, making it easy to track the progress of your data workflows. To gain further insights into the DAG runs, you can switch to the Grid view, where the latest run’s tasks and their statuses are displayed in a structured manner. This view provides a detailed breakdown of each task’s status, offering a clear picture of the job’s execution flow. For even more information, clicking on the Logs link within the Grid view allows you to access the driver logs for each Spark job executed during that run. This user-friendly interface makes it easy to manage, monitor, and troubleshoot your Spark jobs effectively. With the ability to visualize the DAG runs and access the task status and logs, you gain full control and visibility over your data workflows, enabling you to promptly address any potential issues and ensure the successful execution of your data processing pipelines.
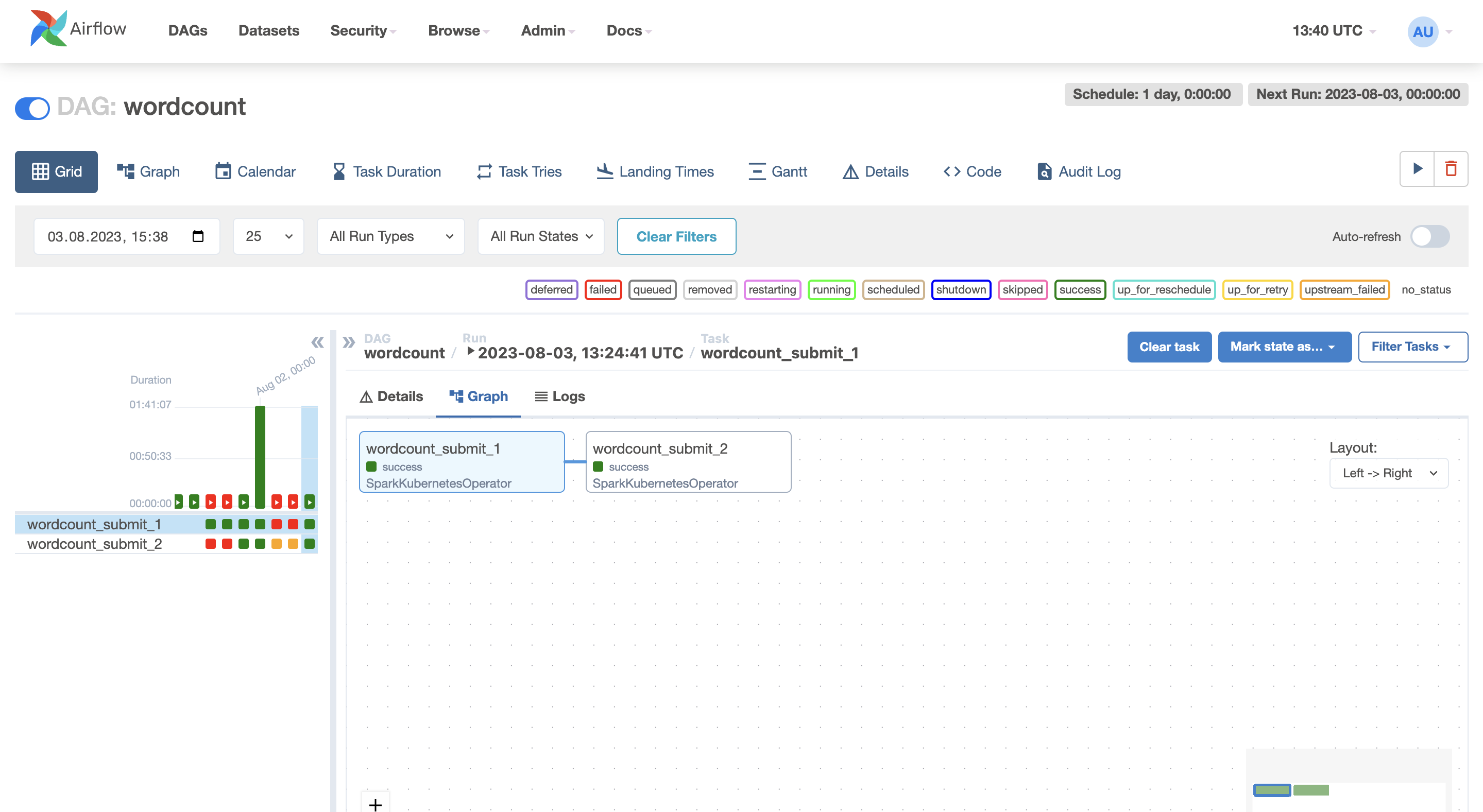

Then, in your Kubernetes instance, you can easily locate the pods related to the Spark job by executing the command:
1
kubectl get sparkapplications
with the output:
1
2
3
NAME STATUS ATTEMPTS START FINISH AGE
my-wordcount-1-20230803t132441-1 COMPLETED 1 2023-08-03T13:24:46Z 2023-08-03T13:25:31Z 25m
my-wordcount-2-20230803t132441-1 COMPLETED 1 2023-08-03T13:25:35Z 2023-08-03T13:26:20Z 25m
Reference link
For more details check out these links: