
Welcome to an exciting adventure where we embark on a journey of transforming a chaotic tangle of notebook code into sleek. In this blog, we’ll dive into the fascinating world of productionizing a document chatbot, starting with a notebook filled with scribbles, half-baked ideas, and untested snippets. Our mission? To take this messy code and transform it into a scalable, reliable, and well-orchestrated system leveraging the power of Kubernetes.
We’ll navigate the intricacies of containerization, orchestration, and deployment. We’ll explore how Kubernetes and Helm, the leading container orchestration platform, comes to our rescue, taming the chaos and turning it into a harmonious symphony. At the heart of it all is a document chatbot, a tool that provides intelligent interactions, guiding users through their document-related needs.
Join us as we delve into the art of productionizing, witnessing the transformation from spaghetti code to sleek Kubernetes pods.

In this blog, we will productionize the document chat agent created in The game of LLM Throne. So the idea is to create a set of microservices for managing the acquisition of the text, storing into DB vector and a UI for chatting with the agent. We will use the following tools:
- FastAPI: web framework for building APIs.
- Docker,Kubernetes and helm: for deploying the microservice into azure cluster.
- Streamlit: for the creation of web UI apps in minutes.
The Python code of the microservices is the same as described in the post:The game of LLM Throne so we will not describe the code but you can read it on github repository: DocuChat.
So let’s see the architecture:
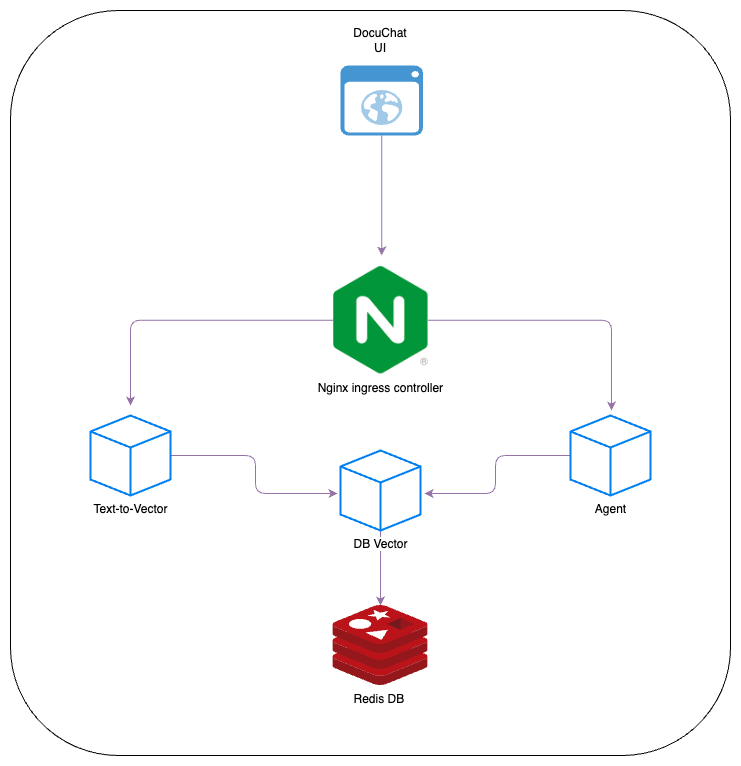
Each cube represents a microservices:
- We use Redis as Vector DB and the microservice DB Vector manages the storing and retrieving data to DB. Also, this service is not exposed to external as it is used by the others service.
- Text-To-Vector service manage the storing of chunks of text. It takes a long text and it split in chunks and store the chunks into the DB Vector calling the DB Vector service
- The Agent service manage the queries with the LLM model.
MicroServices and Docker
FastApi
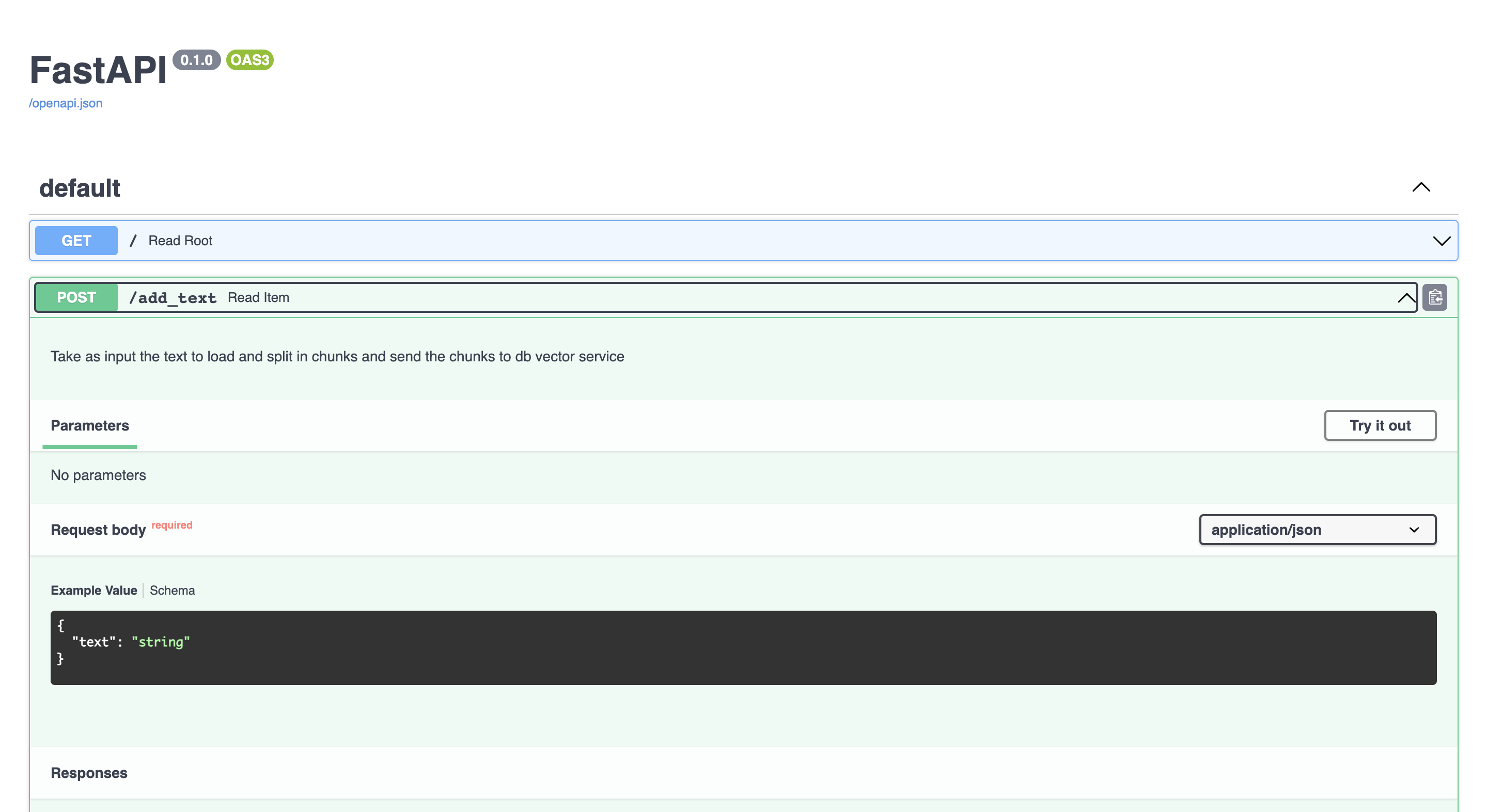
Each service is a python script that uses the FastAPI framework web framework for building fast and high-performance APIs. It is designed to be fast, easy to use, and highly efficient. A cool feature of FastAPI is that offers interactive API documentation making it an ideal choice for building scalable and production-ready APIs. So with a few lines, we can build API and also automatically an interactive API documentation that describes the structure and data models of the defined API. And also, allows testing and exploring API endpoints directly, making the development and debugging process more efficient.
Then, after the run of the service you can test it using the Interactive API docs: http://127.0.0.1:8000/docs
Docker
For each service, a docker image is created. Each container just installs all the libraries needed for the service and runs the service.
Dockerfile of text-to-vec service:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
FROM python:3.8
RUN apt update
EXPOSE 8000
WORKDIR /service/
COPY main.py .
COPY entrypoint.sh .
COPY requirements.txt .
RUN chmod +x ./entrypoint.sh
RUN pip install -r requirements.txt
ENTRYPOINT ["./entrypoint.sh"]
Where entrypoint.sh:
1
uvicorn main:app --host 0.0.0.0 --port 8000 --root-path /text-to-vec
NOTE: I set the –root-path option because in my kubernetes clusters the ingress rules redirect all the URL that starts with /text-to-vec to the text to vector service (this is configured also in the other exposed services). Because the services are unaware of that you need to specify the root path option in case of use a proxy server.
Since I want to deploy all the services inside Azure Kubernetes Service I build the image inside the azure container registry but you can also build locally.
NOTE 2: The connection of each services works with Environment variables. So please look into the README file inside the services folder (Example ).
Kubernetes and Helm
After the creation of the docker images we are ready to create the pods. For this purpose we use Kubernetes: an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Kubernetes allows you to define and manage complex application deployments, networking, storage, and other resources using declarative configurations. Together with Kubernetes, we use also Helm: a package manager for Kubernetes that simplifies the deployment and management of applications and services on Kubernetes clusters. It includes templates for Kubernetes manifests, configuration values, and other metadata. Helm charts enable easy application deployment, versioning, and customization, allowing users to install, upgrade, and manage applications on Kubernetes using a simple command-line interface.
Helm chart is defined in the folder docuchat, where:
- values.yml: defines the all parameters
- templates/deployment.yaml: defines the pods
- templates/service.yaml: defines the services
- templates/ingress.yaml: defines the ingress rules
- templates/pvc.yaml: defines the persistence volume claim
Pod and Service
Pod are defined in deployment.yaml file. Each pod is a microservice with different ports exposed and environment variables defined in the values.yaml file. Also each pod have their own service with the same name as the pod.
Persistence Volume
Since Redis service stores all the embedding vectors without a persistence volume each time the pod is redeployed (or recreated) we will lose all the stored data. So, in pvc.yaml we defined a persistence volume claim for Redis: a request to allocate storage resources in a Kubernetes cluster. It is used to dynamically provision and bind storage volumes to a specific pod or container. Then, create a volume (with a PVC) attached to the Redis pod during the deployment in azure kubernetes service, azure will create a new storage disk and it will attach to the Redis pod. With this solution the data of Redis is stored inside the storage disk and it will exist as long the pod exist (uninstalling the chart will also delete the storage disk).
Ingress
As we want to expose some services that are inside our kubernetes cluster we need to create an LoadBalancer. So, for this purpose we use NGINX Ingress Controller. It is an open-source software solution built on top of the NGINX web server. It acts as a reverse proxy and load balancer for routing incoming traffic to Kubernetes clusters. In Kubernetes, the Ingress Controller serves as an entry point for external traffic to access services within the cluster.
With the following commands, we can easily create an NGINX Ingress Controller:
1
2
3
4
5
6
7
NAMESPACE=<Namespace of your deployment>
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx \
--create-namespace \
--namespace $NAMESPACE \
--set controller.service.annotations."service\.beta\.kubernetes\.io/azure-load-balancer-health-probe-request-path"=/healthz
After the creation of ingress-nginx service we can define the ingress rules. An Ingress rule in Kubernetes is a resource that defines how incoming network traffic should be routed to services within a cluster. It acts as a configuration mechanism for managing external access to services. The file ingress.yaml defines the routing with for accessing to the services.
Secret
As we are using OpenAI API services for using GPT we need a way to store securly the API authentication token of OpenAI. Kubernetes has a solution for this: Secrets. Kubernetes secrets are a way to securely store and manage sensitive information, such as passwords, API keys, and certificates, within a Kubernetes cluster. Secrets are specifically designed to protect sensitive data from being exposed or stored in plain text within containerized applications.
So, before to deploy our chart we need to store the OpenAI API token:
1
2
OPENAI_API_KEY=<YOUR_TOKEN>
kubectl create secret generic openai-token --from-literal=token=$OPENAI_API_KEY --namespace $NAMESPACE
This secret are injected into the envirnment variable of the pod definition:
1
2
3
4
5
6
7
8
...
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-token
key: token
...

UI
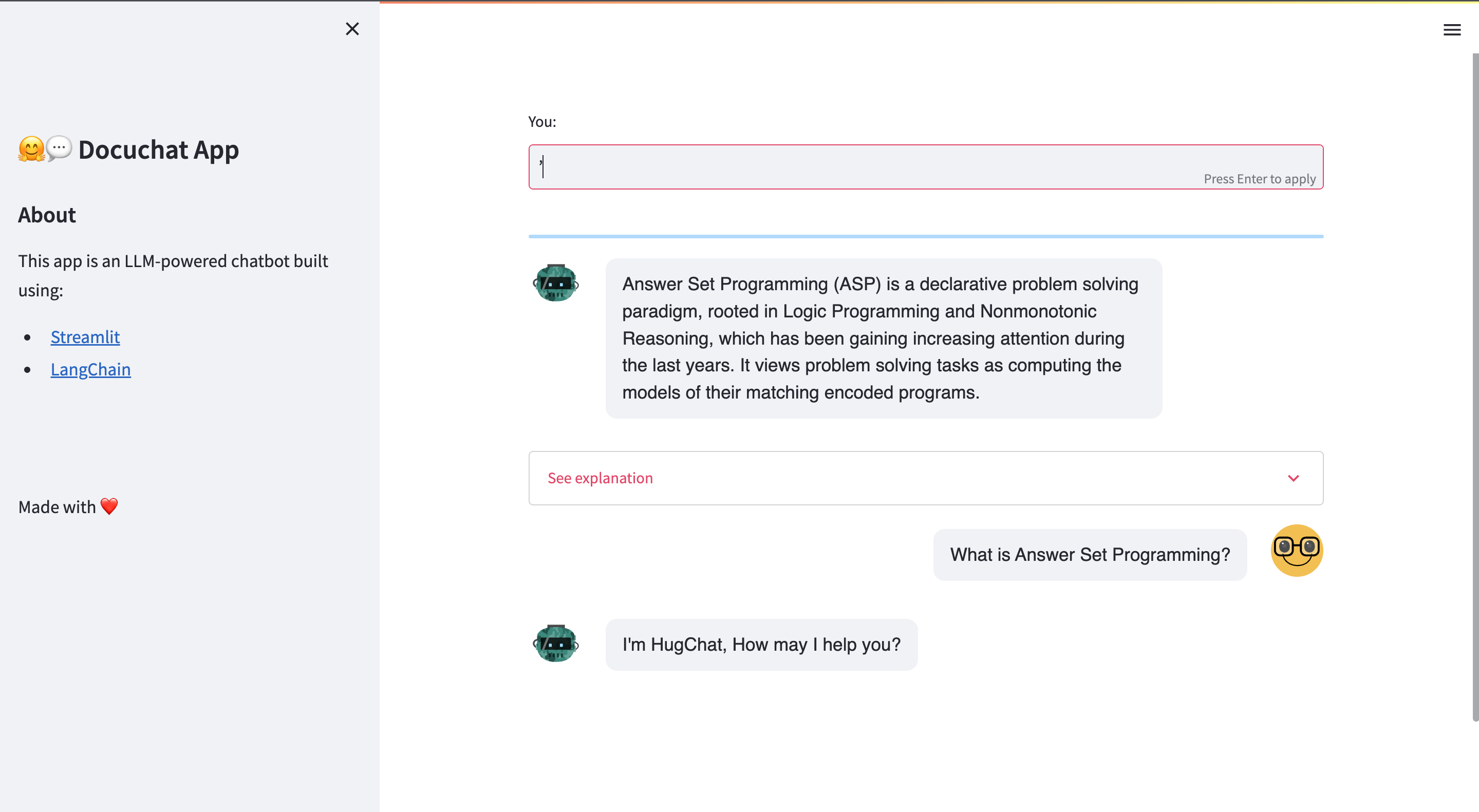
The last piece of our system is the UI, a simple chat created using Streamlit that will allow to query our documents. Streamlit is an open-source Python library that simplifies the creation of interactive web applications. It allows us to build intuitive UIs and visualize data without the need for extensive web development knowledge. With Streamlit, we can quickly prototype and deploy our web UI interface with minimal effort.
Furthermore, in order to understand the answer of our agent the UI also display the chunks of the used by the LLM to reply to the our question (See explanation tab).
Github Repository
You could find the code of the services and the definition of the helm chart -> DocuChat

Reference link
For more details check out these links: