
In this post, we will explore the wonderful world of Large Language Models (LLMs) and their potential for building innovative applications!
As we dive into the realm of LLMs, like the battle for the Iron Throne, there’s an ongoing rivalry between Big Tech companies competing to create the ultimate large language model. But fear not, dear reader, for our journey, will be much more enjoyable and less deadly than that of the Seven Kingdoms. So grab your keyboard and let’s embark on this exciting adventure.

For those who don’t know, ChatGPT is a large language model trained by OpenAI based on the GPT (Generative Pre-trained Transformer) model and is revolutionary because it represents a major breakthrough in the field of natural language processing and artificial intelligence. It can understand natural language, generate human-like responses, and perform a wide range of language-related tasks. Unlike traditional chatbots, which rely on pre-programmed responses and decision trees, ChatGPT uses deep learning algorithms (transformers and ) to learn from vast amounts of text data. This allows it to generate responses that are not only more natural-sounding but also more personalized and contextually appropriate.
In this blog post, we will use the power of GPT models using the OpenAI API to build a chatbot with your own data and documents! So, let’s deep dive into the architecture of the chatbot:
But first,
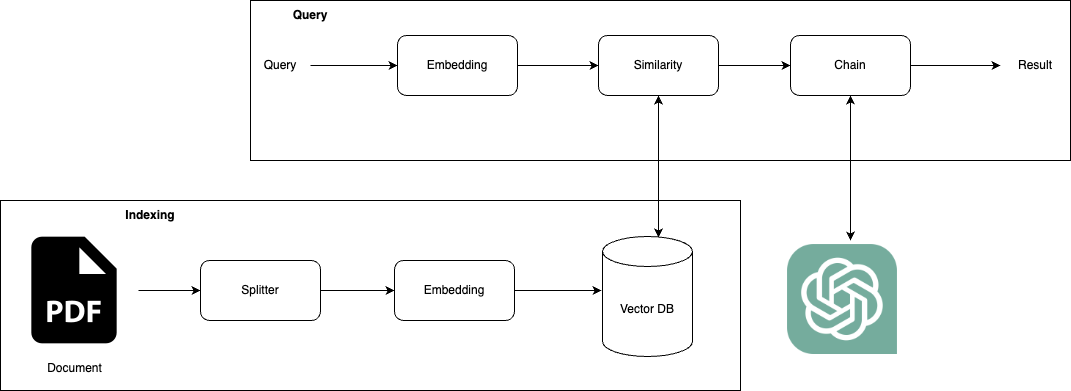
The architecture is divided into two phases:
- Indexing
- Query
The indexing phase parse your documents and then split into multiple chunks of text. Therefore, each chunk is transformed in vectors of numbers using embedding model and stored in a Vector Database. So, the first phase actually index your text data while the second phase query your data transforming first the query (the imput prompt text) into a vector of numbers using the same embedding model used in the first phase. Then, the embedded query is searched within the vector database to identify the most similar text chunks that were indexed in the previous phase. The GPT model is then used to generate a response by utilizing both the query and the finded text chunks.
For the building of the chatbot we use LangChain framwork in Colab notebook. Wait… What the hell is LangChain? LangChain is a framework that facilitates the development of applications powered by language models. It focuses on enabling language models to interact with data sources and their environment. The framework consists of various modules that serve as building blocks for language model-powered applications. These modules include Models, Prompts (for prompt management and optimization), Memory (to persist state between calls), Indexes (for working with external data), Chains (structured sequences of calls), Agents (Chains with high-level directives), Callbacks (for logging and streaming intermediate steps), and more. The framework also integrates with various language models, systems, and products.
Indexing your document
Let’s import all the libs the we need:
1
2
3
4
5
!pip install langchain
!pip install openai
!pip install pypdf
!pip install tiktoken
!pip install chromadb
And also we need to set the OpenAI API token:
1
2
import os
os.environ["OPENAI_API_KEY"] = "<YOUR OPENAI API TOKEN>"
Embedding
Now we can load our documents. In my example, I loaded a pdf (an interesting research article about Anwer set programming ) of 72 pages.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
import re
from langchain.text_splitter import NLTKTextSplitter
import nltk
nltk.download('punkt')
pdf="/content/Answer_Set_Programming_A_Primer.pdf"
pdf_text = ""
loader = PyPDFLoader(pdf)
documents = loader.load()
for doc in documents:
text = doc.page_content
pdf_text += text
We are now able to split the text into small chunks. For doing that we can use NLTKTextSplitter that use the library NLTK for split the text base on tokenizers (special characters and punctuation).
1
2
3
4
5
6
text_splitter = NLTKTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(pdf_text)
print("Chunks: ",len(texts))
print("Example of chunk:")
print(texts[6])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Chunks: 234
Example of chunk:
For instance, one can think of having access to appropriate means for directly
describing the problem at hand in a declarative specification.
This specification, if
properly polished from ambiguities of natural language and expressed in a proper syntax,
would be not much different in its meaning from the formulation of Sudoku of our
3This game has nowadays worldwide popularity, and world and national championships are held
in big tournaments each year across Europe.
4To date, many variants of Sudoku emerged, like, e.g., color-Sudoku, Samurai-Sudoku, etc.
2example.
Also, such a specification could be automatically executed , in the sense that
some computational engine takes this specification as input , together with a problem
instance, and then produces a solution as output .
So, we have 234 chunks of text and now we are ready to transform each chunk into a vectors of numbers.
Vector DB
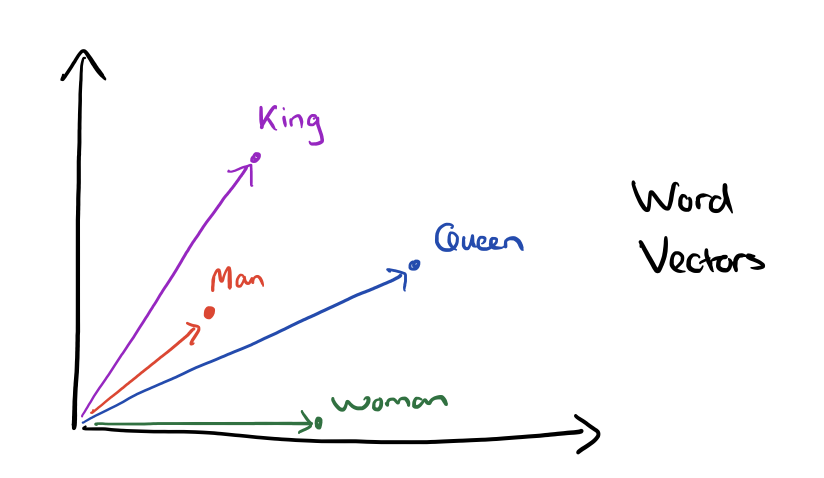
Text embedding is a technique used in natural language processing to represent words or phrases in a numerical vector format. This allows machine learning models to process and analyze text data, as the numerical vectors can be manipulated mathematically to identify similarities and differences between words or phrases. For example, the cosine similarity between the vectors for “king” and “queen” is high, as is the similarity between the vectors for “man” and “woman”. We can also observe a difference in the direction of the vectors for “king” and “queen” compared to “man” and “woman”. This reflects a semantic difference between the words that goes beyond gender. Specifically, “king” and “queen” are related to monarchy and royalty, whereas “man” and “woman” are related to gender identity.
For text embedding, we use the OpenAIEmbeddings class that use the OpenAI text-embedding-ada-002 model that always transforms your text into a 1536-dimensional embedding vector. This numerical vector will be stored in a Vector Database. Vector DB is purpose-built to handle the structure of vector embeddings. They index vectors for easy search and retrieval by comparing values and finding those that are most similar to one another. We will use chroma database, a AI-native open-source embedding database.

1
2
3
4
5
6
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings)
Query
Embedding the query
The first step of the query phase is to transform the user input query into a vector embedding and then search for similar texts inside the vector DB. This step can be done with a few lines of code:
1
2
3
4
5
6
query="Give me an example of real appplication of ASP."
docs = docsearch.similarity_search(query)
context = ""
for doc in docs:
context += doc.page_content
Now inside the context variable we have the context extracted from the pdf to answer the question. Let’s see how to build the final answer using a llm model.
LangChain Prompt
Another feature of LangChain is Prompt Templates. Instead of using directly an LLM model you can take the user’s input, formulate a prompt, and then feed that to the LLM. For example:
1
2
3
4
5
6
7
8
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
And then you can create a very simple chain that will take input, format the prompt, and then send it to the LLM:
1
2
3
4
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
chain.run("colorful socks")
Langchain predefines several prompt templates for different scenarios and we will use the Vector DB Question Answering Prompt. The prompt template takes 2 input variables (context and question) and the text is:
1
2
3
4
5
6
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:
Therefore, we can create a chain with the prompt template:
1
2
3
4
5
6
7
8
9
from langchain.llms import OpenAI
from langchain import PromptTemplate
from langchain.prompts import load_prompt
from langchain.chains import LLMChain
llm = OpenAI(temperature=0.0)
prompt = load_prompt("lc://prompts/vector_db_qa/prompt.json")
chain = LLMChain(llm=llm, prompt=prompt)
The Chatbot
Let’s recap our code and make some test:
For the first phase (Indexing):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
import re
from langchain.text_splitter import NLTKTextSplitter
import nltk
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
nltk.download('punkt')
pdf="/content/Answer_Set_Programming_A_Primer.pdf"
pdf_text = ""
loader = PyPDFLoader(pdf)
documents = loader.load()
for doc in documents:
text = doc.page_content
pdf_text += text
text_splitter = NLTKTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(pdf_text)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings)
Then, for the second phase let’s create our chain:
1
2
3
4
5
6
7
8
9
from langchain.llms import OpenAI
from langchain import PromptTemplate
from langchain.prompts import load_prompt
from langchain.chains import LLMChain
llm = OpenAI(temperature=0.0)
prompt = load_prompt("lc://prompts/vector_db_qa/prompt.json")
chain = LLMChain(llm=llm, prompt=prompt)
And now we have all the ingredients to test our bot:
1
2
3
4
5
6
7
8
9
query="Give me an example of real appplication of ASP."
docs = docsearch.similarity_search(query)
context = ""
for doc in docs:
context += doc.page_content
response = chain.run(question=query, context=context)
print(response)
1
2
3
4
5
6
ASP has been successfully applied to numerous problems in a range of areas including diagnosis,
information integration, constraint satisfaction, reasoning about actions (including planning),
routing, and scheduling, phylogeny construction, security analysis, configuration, computer-aided
verification, health care, biomedicine and biology, Semantic Web,
knowledge management, text mining and classification, and question answering
Final thoughts
In our chatbot, we used the OpenAI models but you can use whatever LLM models and embedding models. For example, on Hugging Face you can find a lot of open-source models (like Stanford alpaca od databricks dolly). LangChain supports as well Hugging Face models with:
- langchain.llms.HuggingFacePipeline for llm models
- langchain.embeddings.HuggingFaceEmbeddings for embeddings models
In conclusion, while we have focused on using Chroma DB several other vector databases can be used (like Redis, Elasticsearch and Pinecone). Moreover, by utilizing the power of large language models (LLMs), we can create chatbots that can process and analyze our documents with remarkable accuracy and efficiency. With just a few lines of code, we can build powerful AI applications that can help us automate tasks and provide valuable insights from our data.
The LLMs is a powerful tool that can help us unlock the potential of our data and transform the way we work with it. By staying up to date with the latest advances in these technologies and exploring new ways to use them, we can continue to push the boundaries of what is possible with data analysis and machine learning.
Reference link
For more details check out these links: